Decision Trees
Einer der grundlegendsten Vertreter eines Algorithmus der Gruppe des überwachten Lernens ist der sogenannte Decision Tree Algorithmus. Dieser Algorithmus ist sehr vielseitig und kann sowohl zur Lösung von Regressions- als auch Klassifikationsproblemen genutzt werden. Wie der Name nahelegt, baut der Computer Entscheidungsbäume auf, um auf deren Grundlage Konsequenzen zu ziehen und so zu lernen.
Was sind Entscheidungsbäume?
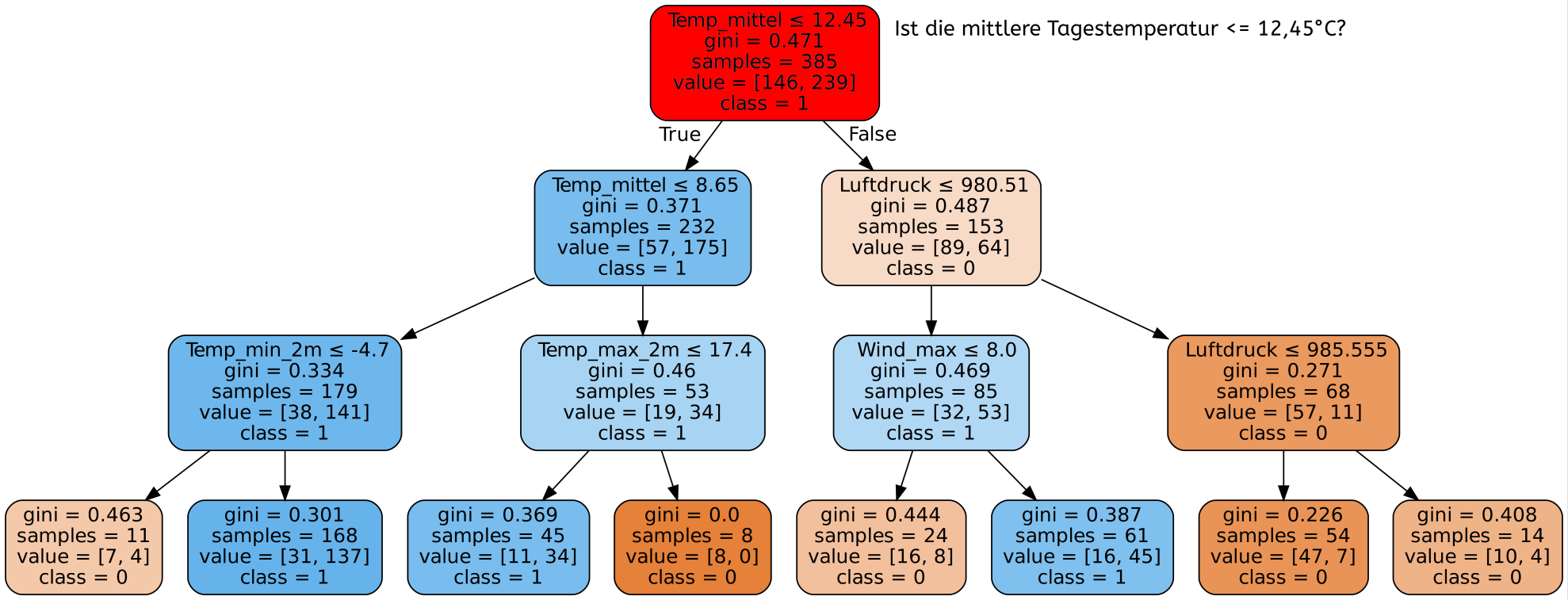
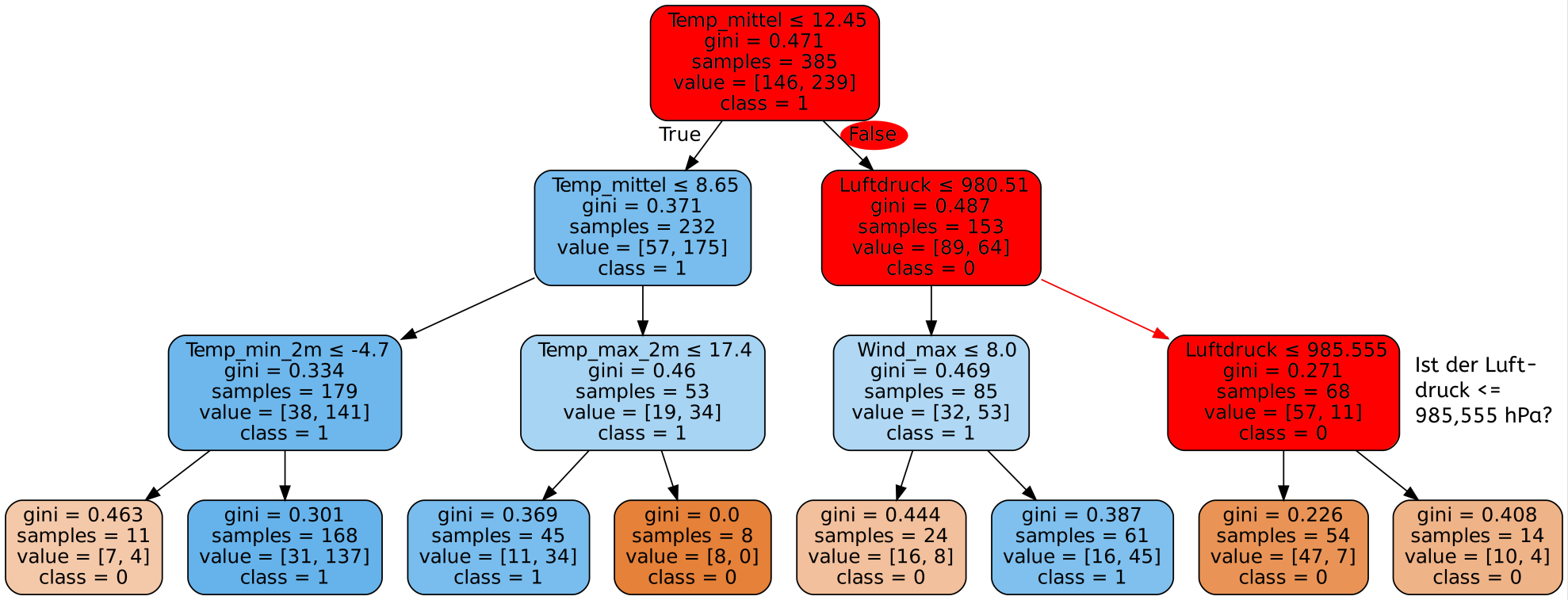
Ein Ausschnitt eines durch den Algorithmus entstandenen Entscheidungsbaums zu einer Wettervorhersage könnte beispielsweise wie folgt aussehen:
Der Decision Tree Algorithmus hat die verfügbaren Wetterdaten analysiert und gelernt, welche Kriterien am aussagekräftigsten sind um herauszufinden ob Niederschläge am entsprechenden Tag wahrscheinlich sind oder nicht. Die beste einzelne Frage zur Unterscheidung ist laut dem Decision Tree Algorithmus, ob der Bedeckungsgrad des Himmels ≤ 3,65 ist. Dies entspricht ungefähr der Unterscheidung zwischen leicht bewölkt und wolkig. Ist die Antwort auf diese Frage Ja, so ist in der Folge die Frage nach der maximalen Windgeschwindigkeit am besten zur Unterscheidung geeignet, ist die Antwort Nein, so bietet sich eine weitere Unterscheidung nach dem Bedeckungsgrad ≤ 6,45 an - ob es also stark bewölkt ist.
Handelt es sich hier um ein Klassifikations- oder ein Regressionsproblem?
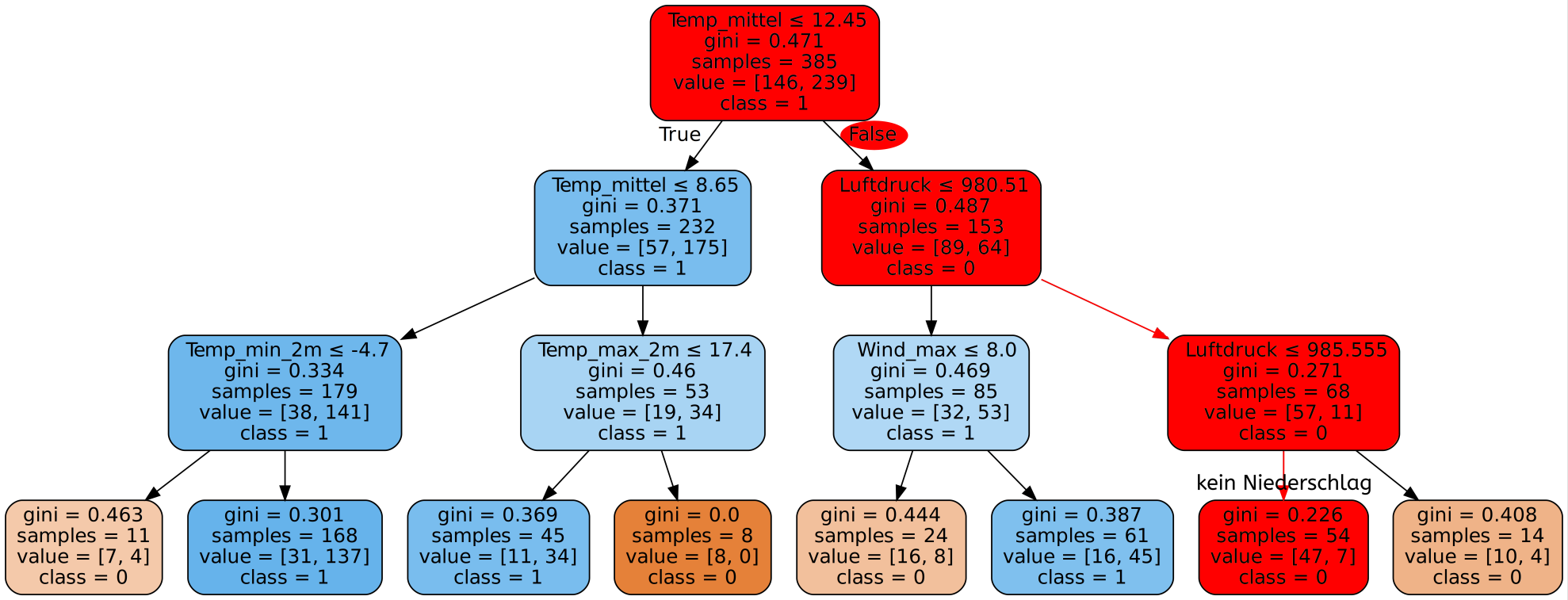
Hätte man nur eine einzige Frage zur Verfügung um zu entscheiden, ob für den zu untersuchenden Tag Niederschlag zu erwarten ist, so würde man am besten die Frage stellen ob die Bedeckung des Himmels ≤ 3,65 ist. Falls ja, so ist die Wahrscheinlichkeit sehr hoch, dass es keinen Niederschlag geben wird, falls nein, so wird es vermutlich Niederschlag geben.
Um das in jedem Schritt beste Unterscheidungskriterium zu finden, benutzt der Decision Tree Algorithmus z.B. den sogenannten Gini-Index. Der Gini-Index ist eine Angabe für den Grad der Homogenität der verbleibenden Datensätze nach dem Split. Die Idee hinter dem Konzept der Homogenität ist, dass je gleichförmiger - also homogener - die Labels der Datensätze nach dem Split in den jeweiligen nachfolgenden Entscheidungen sind, desto besser ist das Kriterium zur Unterscheidung zwischen Tagen mit und ohne Niederschlag geeignet. Je niedriger der Gini-Index ist, desto homogener sind die Daten. Ein Wert von 0,5 bedeutet, dass gleich viele Datensätze mit dem Label Niederschlag wie mit dem Label kein Niederschlag übrig bleiben. Somit trägt ein Split mit einem Gini-Index von 0,5 nicht zur Unterscheidung bei.
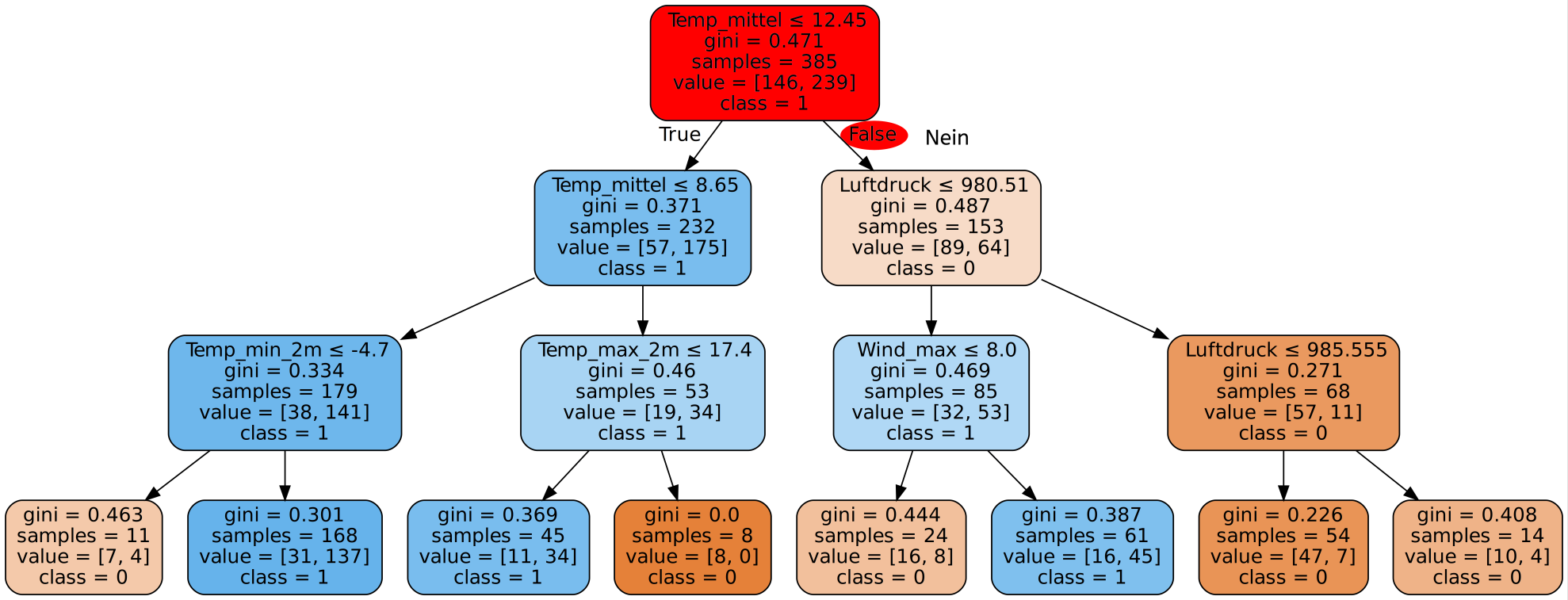
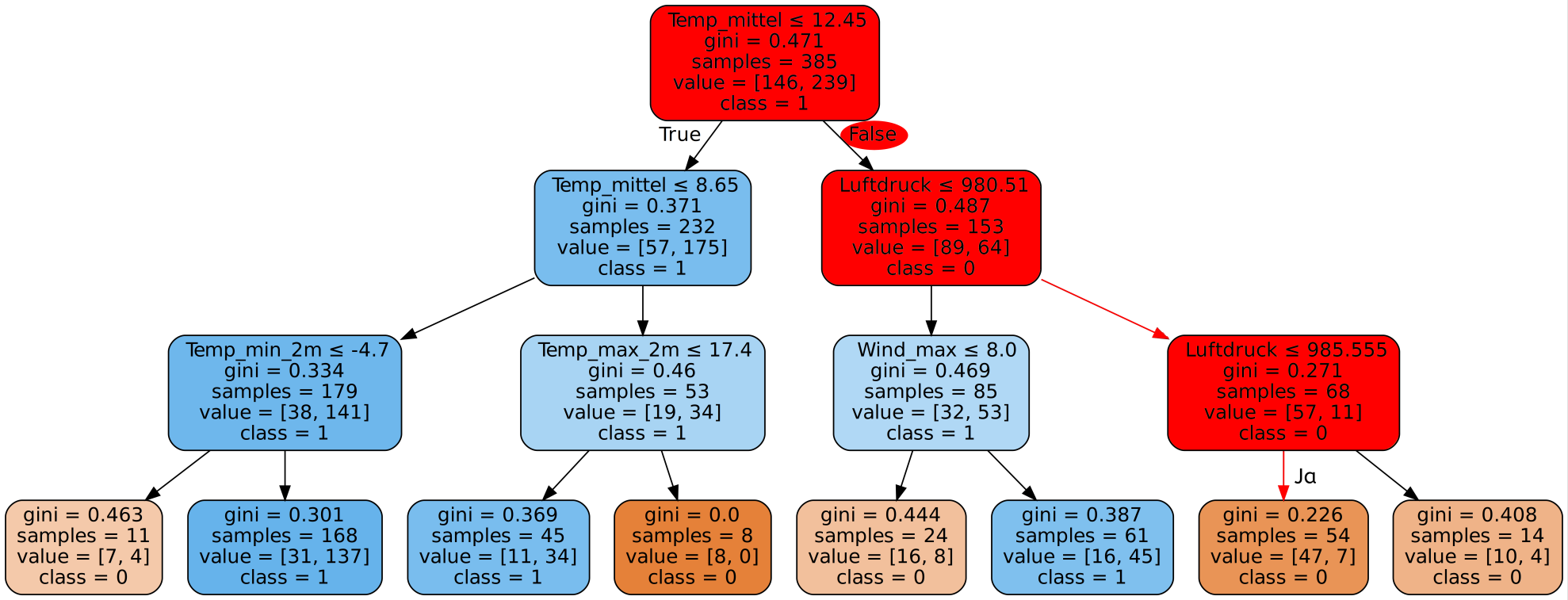
Dieser Entscheidungsbaum, der durch den Decision Tree Algorithmus in der Trainingsphase erstellt wurde, bildet nun die Grundlage für jegliche Entscheidungen des Programms. Erhält das Programm die Daten für einen neuen Tag, so wird es zuerst prüfen, ob der Bedeckungsgrad ≤ 3,65 ist. Dann wird es je nach Ergebnis die maximale Windgeschwindigkeit oder den Bedeckungsgrad genauer betrachten usw. Die erste Frage nennt man die Wurzel des Baums. Am Ende dieser Entscheidungs-Kette erreicht man ein sogenanntes Blatt des Entscheidungsbaums, welches dann angibt, ob (laut Algorithmus) Niederschlag vorhanden ist oder nicht. Die Namen Wurzel und Blatt leiten sich von der Vorstellung ab, dass die kleinsten Elemente eines (Entscheidungs-) Baums Blätter sind und alles aus der Wurzel entspringt. Aus dem Entscheidungsbaum oben ist ein solches Blatt beispielsweise:

Wie könnte der Algorithmus erkennen, dass er in einem Blatt angelangt ist?
Ist man in einem Blatt angekommen, steht die Entscheidung des Algorithmus fest. In diesem Fall würde der Algorithmus bei Erreichen des Blatts davon ausgehen, dass es keinen Niederschlag gibt. Er hat also nur anhand der beiden Fragen nach der Sonnenscheindauer und der mittleren Windgeschwindigkeit seine Entscheidung getroffen. Dies kann er deshalb tun, da es an allen 54 Tagen in den Trainingsdaten, die diese Kombination aus Bedeckungsgrad und Windgeschwindigkeit hatten, keinen Niederschlag gab (class=0).
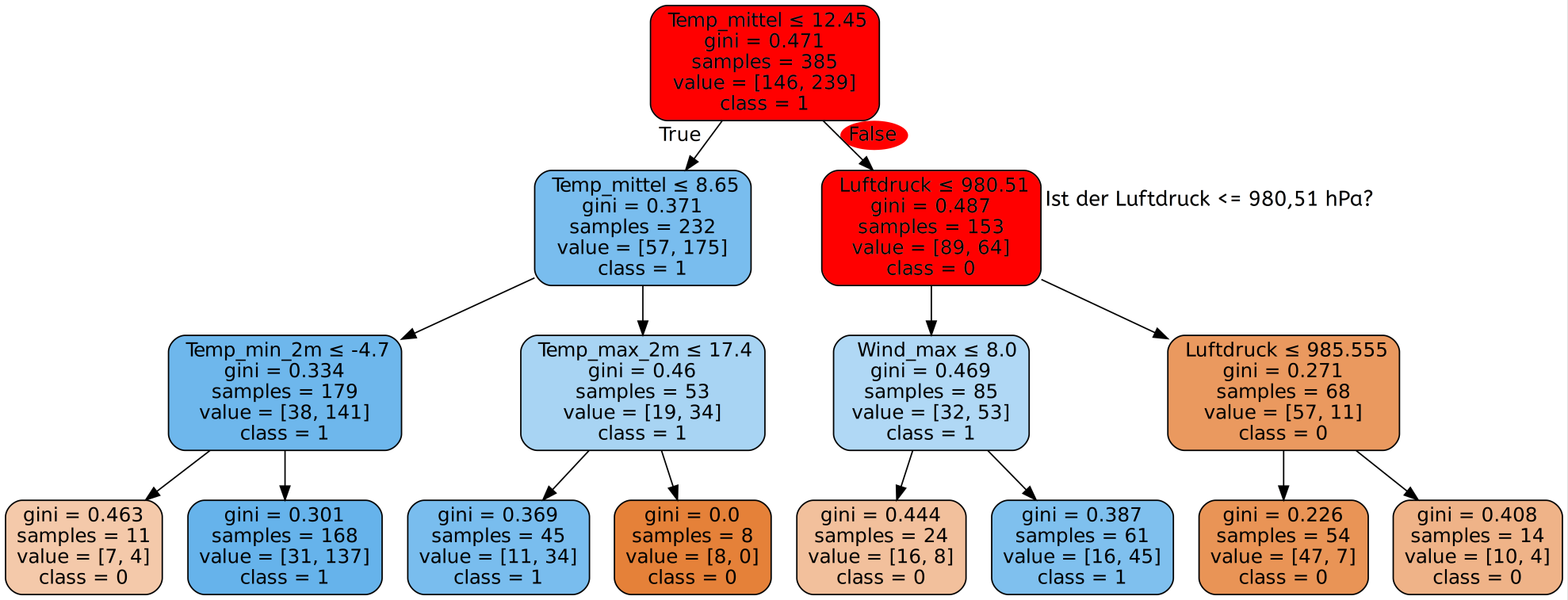
Sobald der Entscheidungsbaum aufgebaut ist, kann das Programm Aussagen treffen, die auf diesem Baum basieren. Das Prinzip der Entscheidungsfindung wird hier verdeutlicht.
Verschiedene Entscheidungsbäume möglich
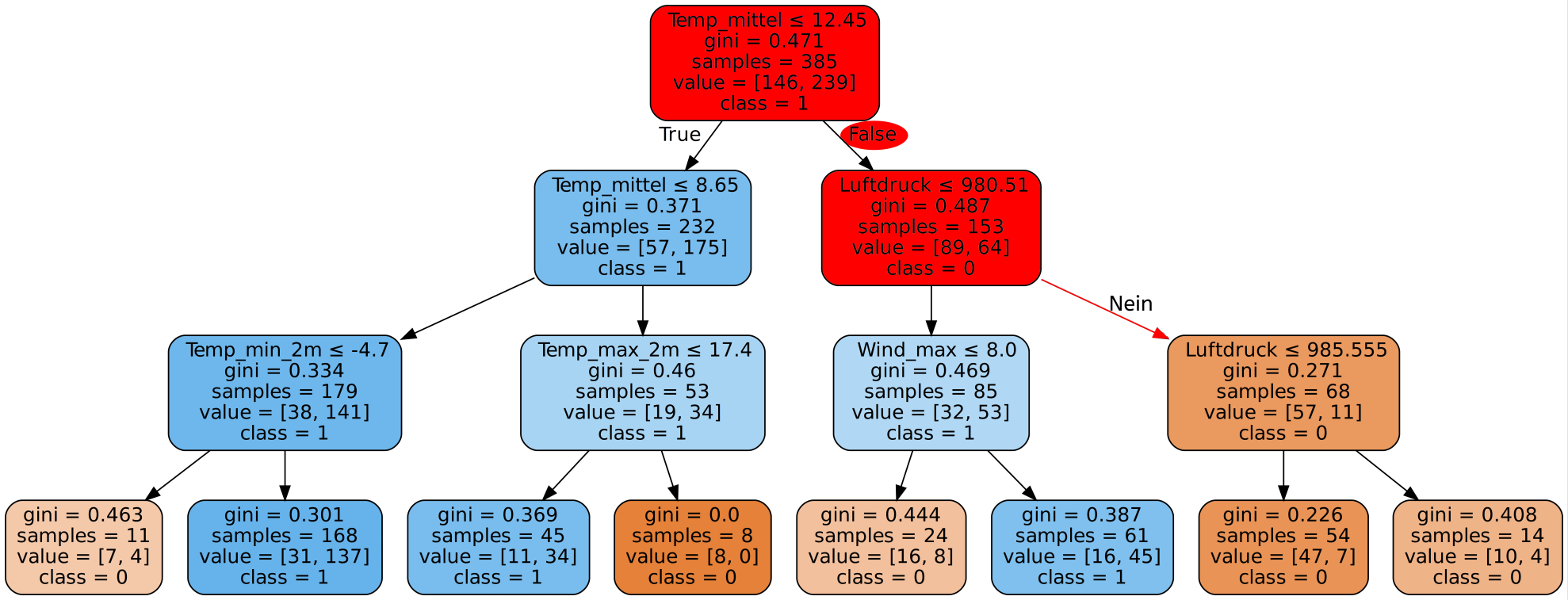
Ist ein Entscheidungsbaum erstellt worden, so steht dieser für das Programm als Entscheidungsgrundlage fest. Allerdings ist das Erstellen dieses Baums nicht eindeutig und für die gleichen Daten können unterschiedliche Entscheidungsbäume existieren.
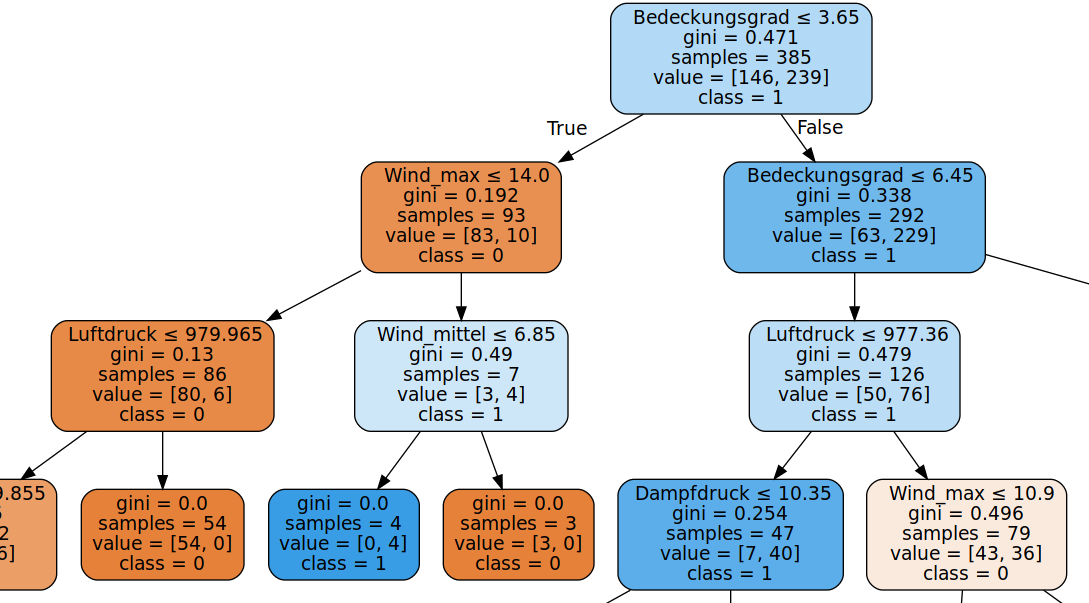
So führt unter anderem die Reihenfolge in der die Kriterien durch den Algorithmus betrachtet werden, zur Entstehung unterschiedlicher Entscheidungsbäume. Ein weiterer Baum für die selben Wetterdaten sieht (ausschnittsweise) beispielsweise so aus:
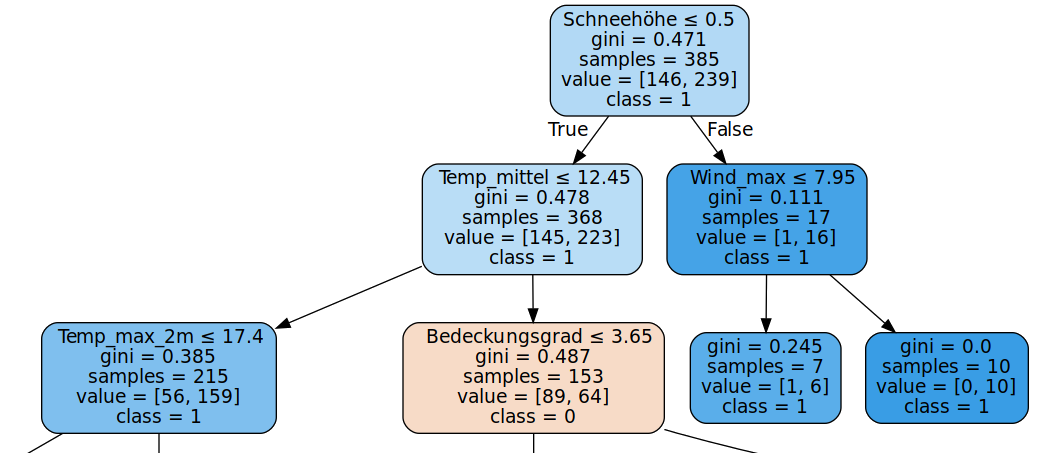
Das gesamte Wissen, welches in den Entscheidungsbaum eingeflossen ist, hat er selbstständig erlernt. Somit ist der Entscheidungsbaum im Prinzip eine Visualisierung des Wissens. Nachdem wir nun also einen Überblick über einen wichtigen Algorithmus des Maschinellen Lernens haben, schauen wir uns in den nächsten Kapiteln ein Beispielprojekt an.