Beispielprojekt
1. Daten finden
Um überhaupt Maschinelles Lernen nutzen zu können benötigen wir natürlich zunächst Daten. Häufig liegt hier schon eine der größten Herausforderungen im gesamten Prozess des Maschinellen Lernens. Um ausreichend gute Vorhersagen treffen zu können und eine hohe Genauigkeit zu erreichen benötigen die meisten Algorithmen große Datenmengen. Um sehr komplexe Aufgaben wie Spracherkennung zu erlernen, befindet man sich schnell im Bereich von mehreren Millionen benötigten Datensätzen.
In unserem kleinen Beispielprojekt schauen wir uns nochmals die schon angesprochenen Wetterdaten an. Glücklicherweise finden sich auf den Servern des Deutschen Wetterdienstes sehr viele historische Daten, sodass wir uns um die Quantität keine Sorgen machen müssen. Auch die Qualität der Daten ist für unsere Zwecke ausreichend, sofern wir keinen Fehler bei der Datenauswahl machen. Unser Ziel ist es für Saarbrücken aufgrund der Daten der letzten Jahre morgens eine Vorhersage darüber treffen zu können, ob es Niederschlag geben wird oder nicht, sofern wir bereits die anderen Daten des bisherigen Tages wie bisherige maximale Windgeschwindigkeit etc. wissen. Würden wir nun dafür auch die Daten einer weiter entfernten Stadt wie zum Beispiel Berlin nutzen, so hätten wir das Problem, dass unsere Daten unter Umständen nicht repräsentativ für Saarbrücken sind und somit durch unser Programm falsche Schlüsse gezogen werden. Also wählen wir lediglich die Daten aus Saarbrücken.
2. Überblick über Daten verschaffen
Wir haben uns nun also sowohl qualitativ als auch quantitativ ausreichend gute Daten besorgt. Nun müssen wir uns diese genauer ansehen. Alle Datensätze haben die folgende Form:

In diesen Datensätzen sind also viele verschiedene Wetterdaten enthalten. Die Spalte Niederschlagsform nimmt dabei eine besondere Stellung ein. Sie ist unsere Zielvariable, also unser Label! 0 bedeutet dabei, dass kein Niederschlag vorhanden ist, 1 bedeutet Niederschlag. Mit Hilfe dieser Angabe können wir einen Algorithmus des überwachten Lernens nutzen.
3. Aufteilen in Trainings- und Testdaten
Nachdem wir eventuelle weitere Schritte unternommen haben, um die Daten für unseren Algorithmus vorzubereiten (z.B. Prüfen, ob alle Werte vorhanden sind), folgt das Aufteilen in Trainings- und Testdaten. Dieser Schritt ist extrem wichtig, um eine möglichst gute Vorhersagegenauigkeit zu erreichen. Leider kann es vorkommen, dass unser Programm zwar eine gute Genauigkeit auf den bereits gegebenen Daten erreicht, auf neuen unbekannten Daten jedoch sehr schlechte Ergebnisse erzielt. Um diesem Problem vorzubeugen gibt es die Möglichkeit, die gegebenen Daten in zwei Teile aufzuteilen. Standardmäßig nimmt man ca. 20%-30% der Datensätze und beachtet diese beim Trainieren des Programms zunächst nicht. Dies sind dann die sogenannten Testdaten. Die restlichen 70%-80%, die Trainingsdaten, werden dem Programm zum Lernen übergeben.

Dieses Vorgehen versetzt den Entwickler auf einfache Art und Weise in die Lage die Qualität der Vorhersagen zu überprüfen. Die Testdaten (ohne ihre Labels) sind für das Programm "neue" Daten, dem Entwickler sind jedoch die richtigen Labels bekannt und somit ist die Genauigkeit des Programms feststellbar. Sollten hierbei zu große Ungenauigkeiten auffallen, können - und sollten - weitere Schritte zur Optimierung vorgenommen werden.
4. Auswahl des Algorithmus
Nun können wir uns überlegen, welcher Algorithmus für unsere Zwecke am sinnvollsten ist.
Wie wir bereits bemerkt haben können wir überwachtes Lernen nutzen und können beispielsweise einen Decision Tree vom Computer erstellen lassen.
5. Trainieren des Programms
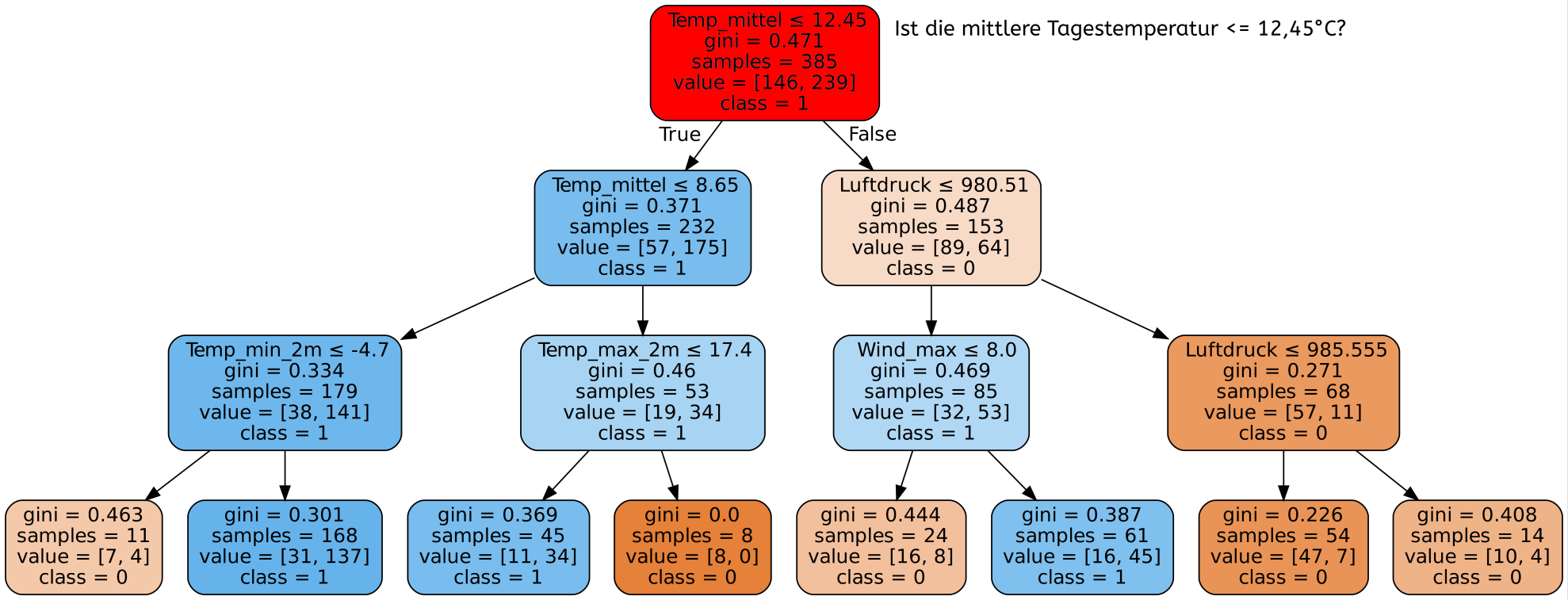
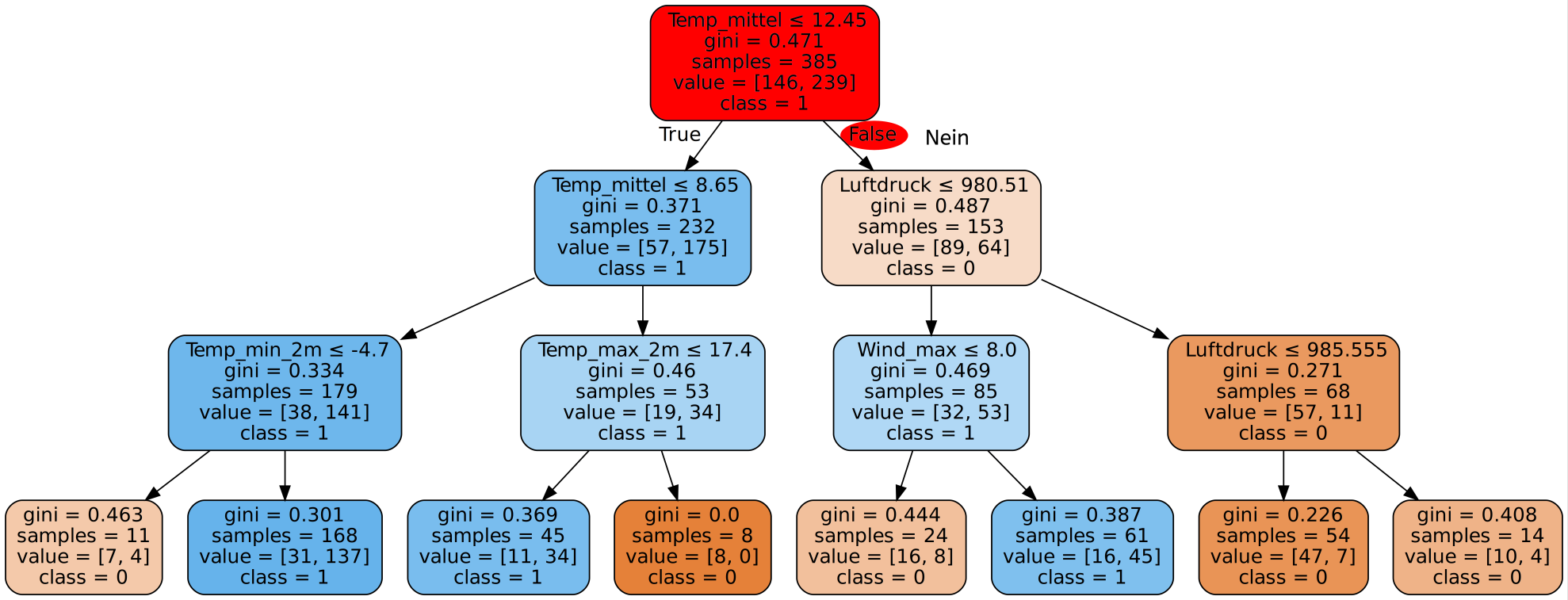
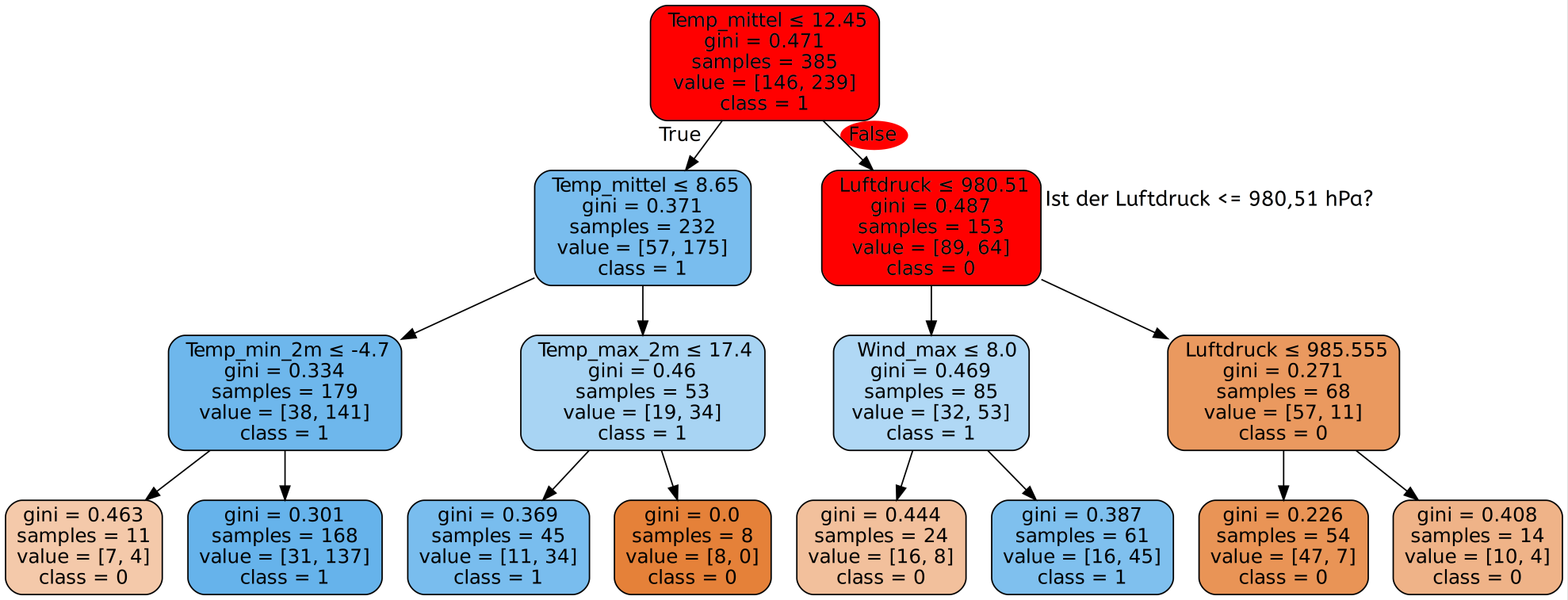
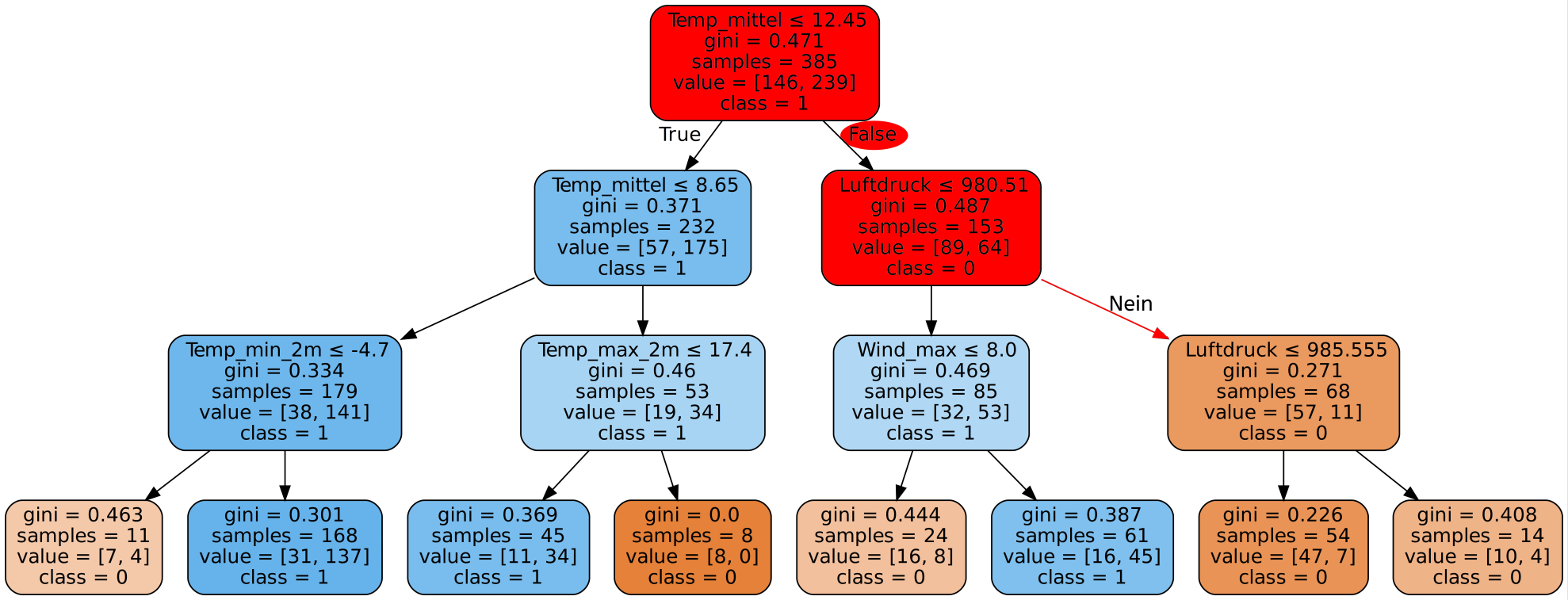
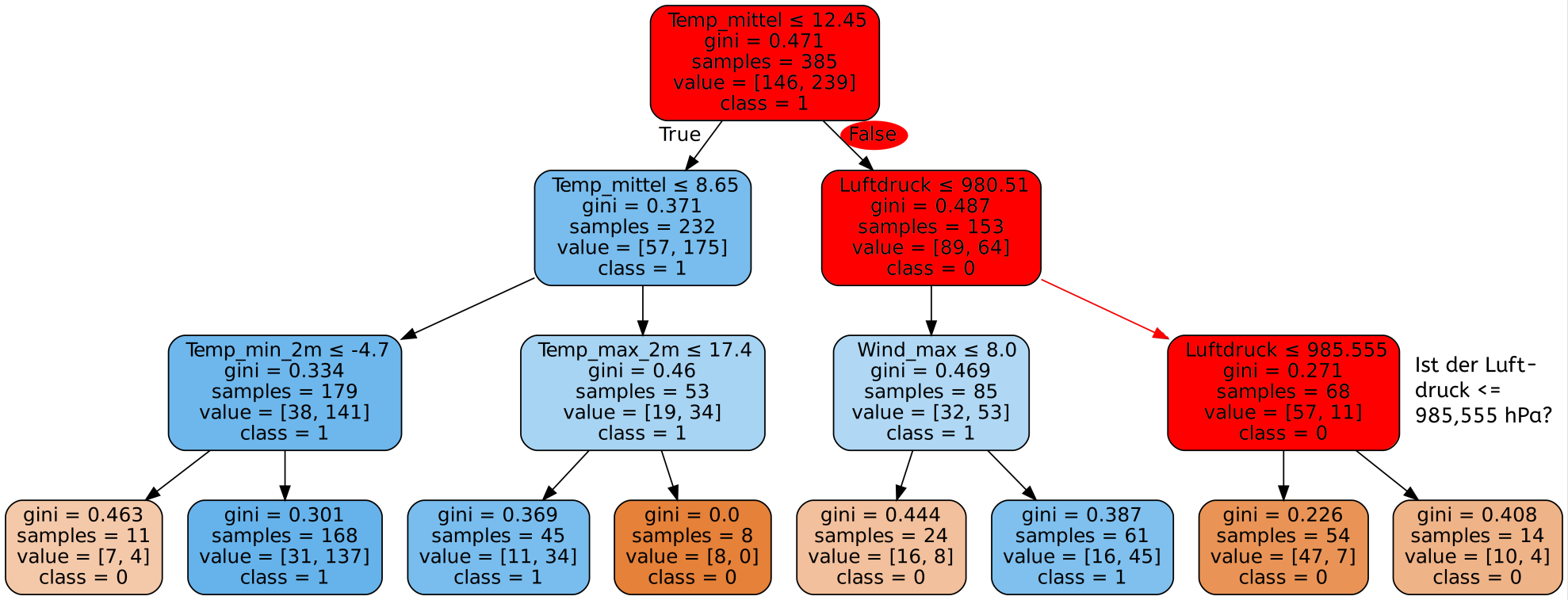
Nun muss der Decision Tree erstellt werden. Dazu müssen wir dem Algorithmus die Trainingsdaten zur Verfügung stellen. Ein möglicher Decision Tree sieht dann wie folgt aus:
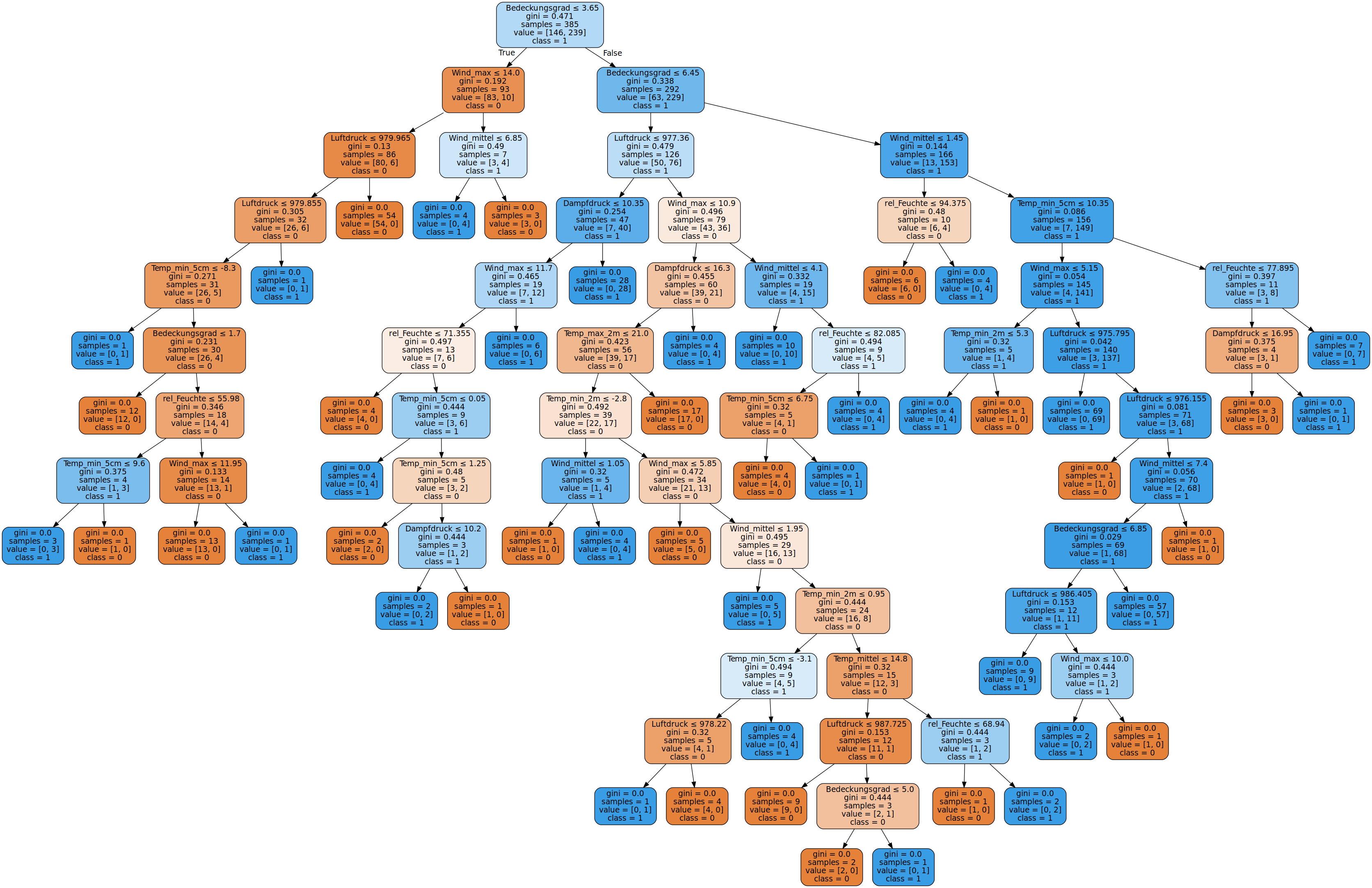
Wie wir sehen, kann solch ein Decision Tree selbst bei wenigen Merkmalen - in unserem Fall 11 - sehr komplex werden. Es wurde hier zur Visualisierung sogar nur ein Teil der Datensätze benutzt. Mit den gesamten Daten wäre der Baum für die Webseite wesentlich zu groß.
Als nächstes sehen wir uns erste Ergebnisse an, die wir mit dem gerade erstellten Decision Tree erreichen.