Parameter
Welche weiteren Parameter gibt es bei Decision Trees?
Parameter sind Eigenschaften des Entscheidungsbaums die durch den Programmierer festgelegt werden können. Dabei wird die Art und Weise wie der Baum aufgebaut wird durch die Werte der Parameter beeinflusst. Dadurch entstehen unterschiedliche Entscheidungsbäume die unterschiedliche Vorhersagen zur Folge haben (können).
Die wichtigsten Parameter von Decision Trees (neben dem Schwellenwert) sind:
- max_depth
- max_features
- min_samples_leaf
- min_samples_split
Wie wird der Entscheidungsbaum durch die Parameter beeinflusst?
1. max_depth
Dieser Parameter gibt die maximale Tiefe des Baums an. Je größer die Tiefe des Baums ist, desto mehr Entscheidungen werden berücksichtigt. Damit steigt auch die Anzahl der möglichen Aufteilungen - der sogenannten Splits - der einzelnen Datensätze und somit die Menge an Informationen die aus den Daten gelernt werden.


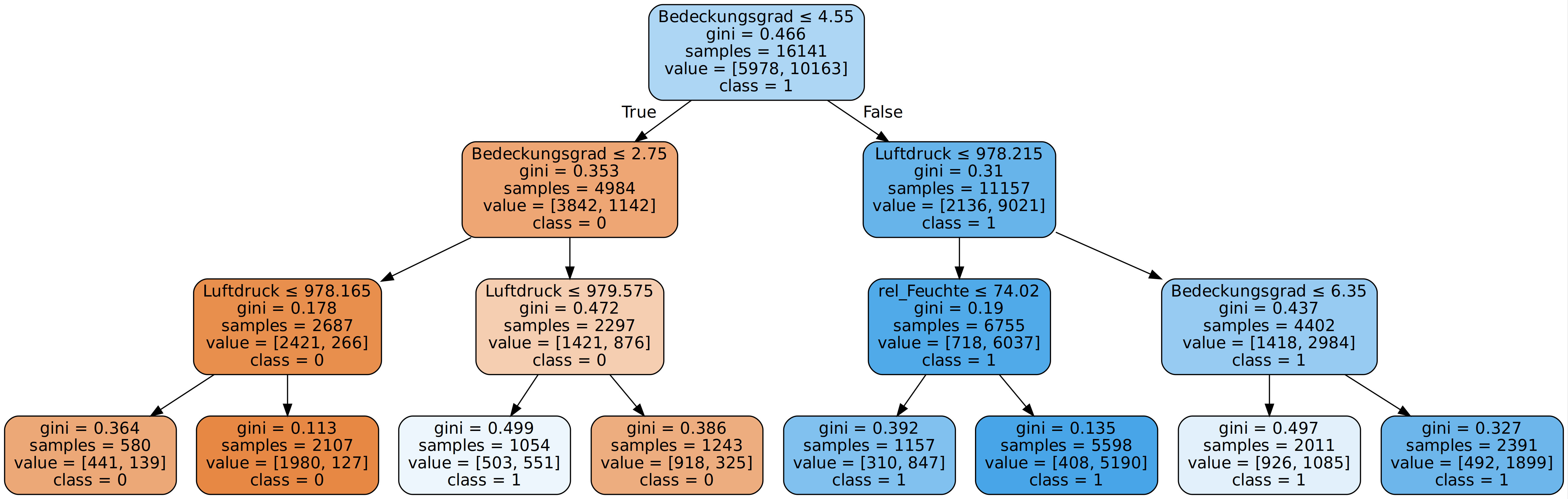
2. max_features
Mit Hilfe von max_features lässt sich festlegen, wie viele Spalten, also Features, in jedem Split maximal berücksichtigt werden sollen um den besten Split zu finden.
3. min_samples_leaf
Der Parameter min_samples_leaf bestimmt die minimale Anzahl an Datensätzen die in einem Blatt des Entscheidungsbaums vorhanden sein müssen.
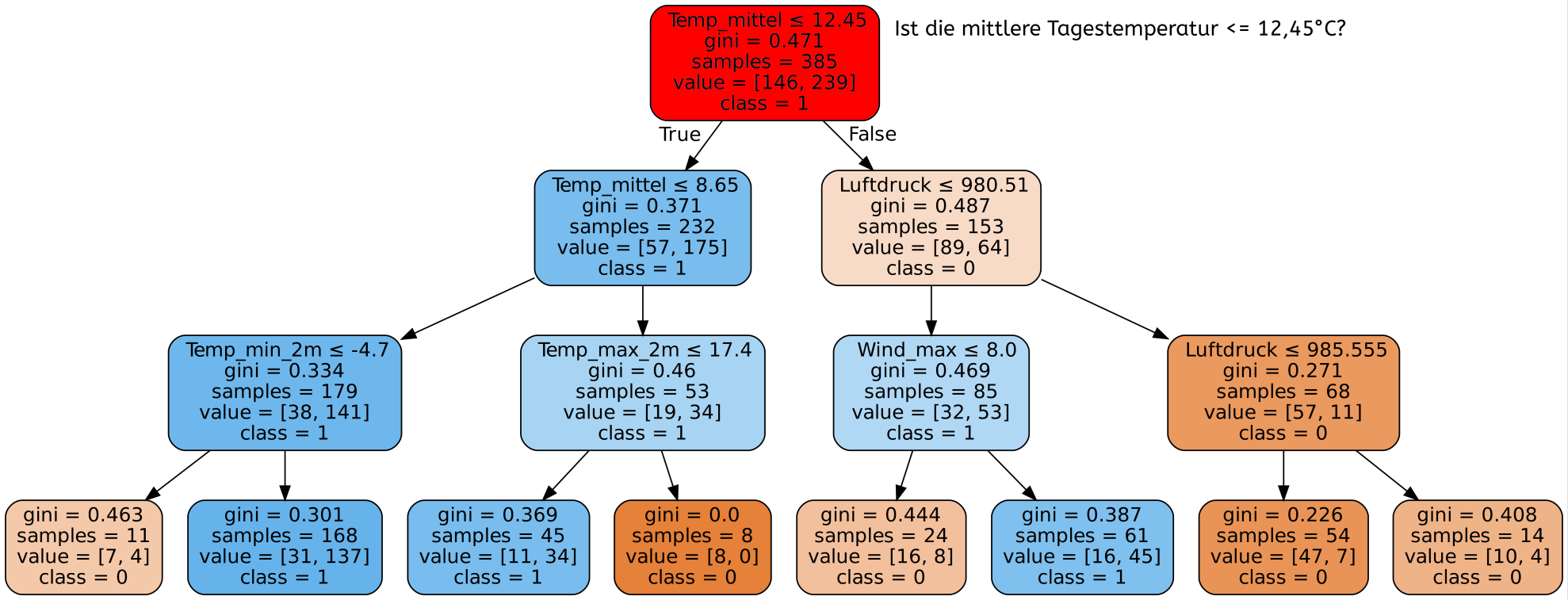
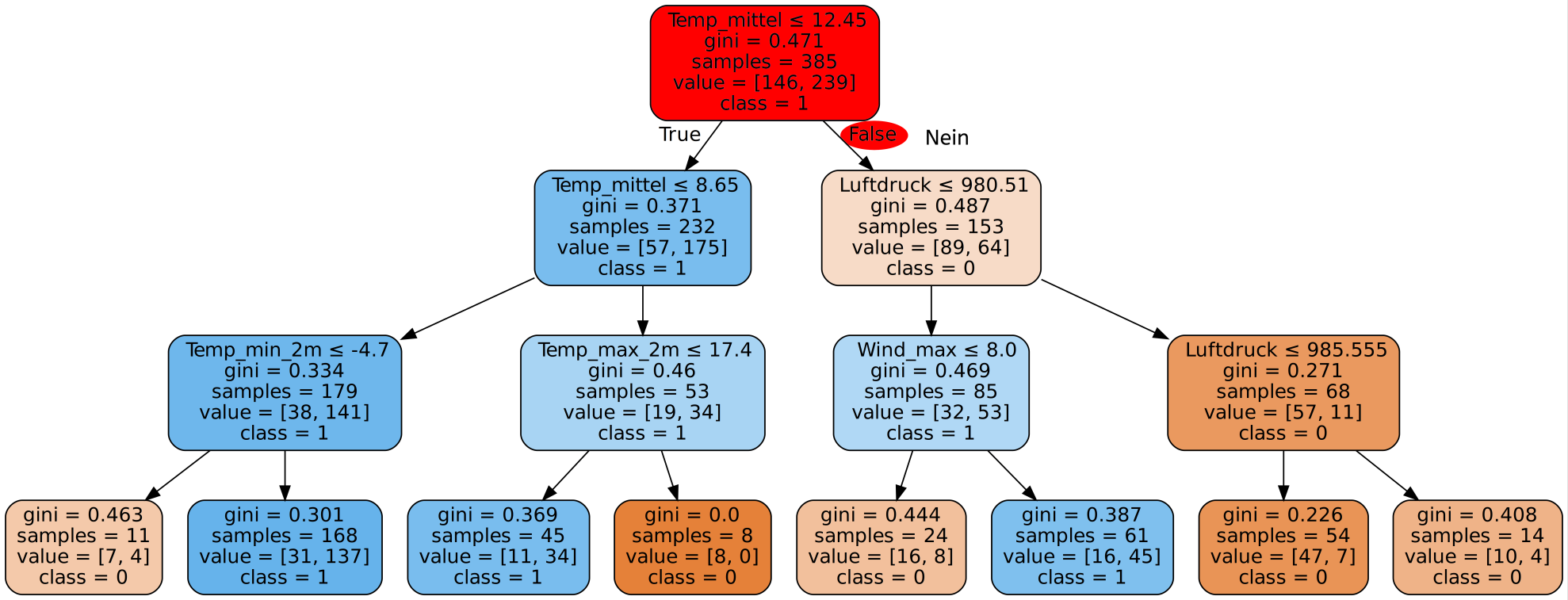
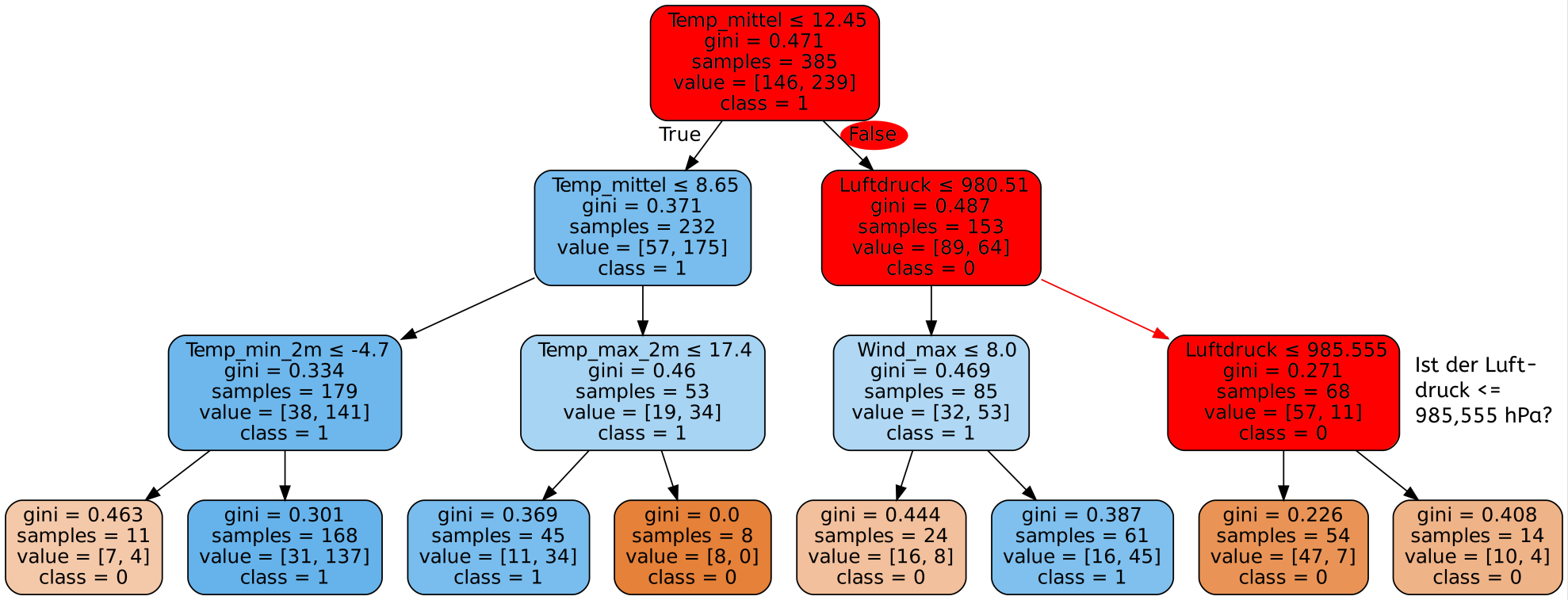
Was ist das Blatt eines Entscheidungsbaums?
Von dieser Zahl ist der Aufbau des gesamten Entscheidungsbaums betroffen. Ein Split an egal welcher Position im Entscheidungsbaum wird nur dann berücksichtigt, wenn beim daraus resultierenden Baum sowohl im linken als auch im rechten Teilbaum mindestens so viele Datensätze vorhanden sind wie min_samples_leaf vorgibt. Wäre diese Bedingung nicht erfüllt, könnten in den folgenden Blättern unmöglich so viele Datensätze wie vorgegeben sein.
Beispiel:
min_samples_leaf=30

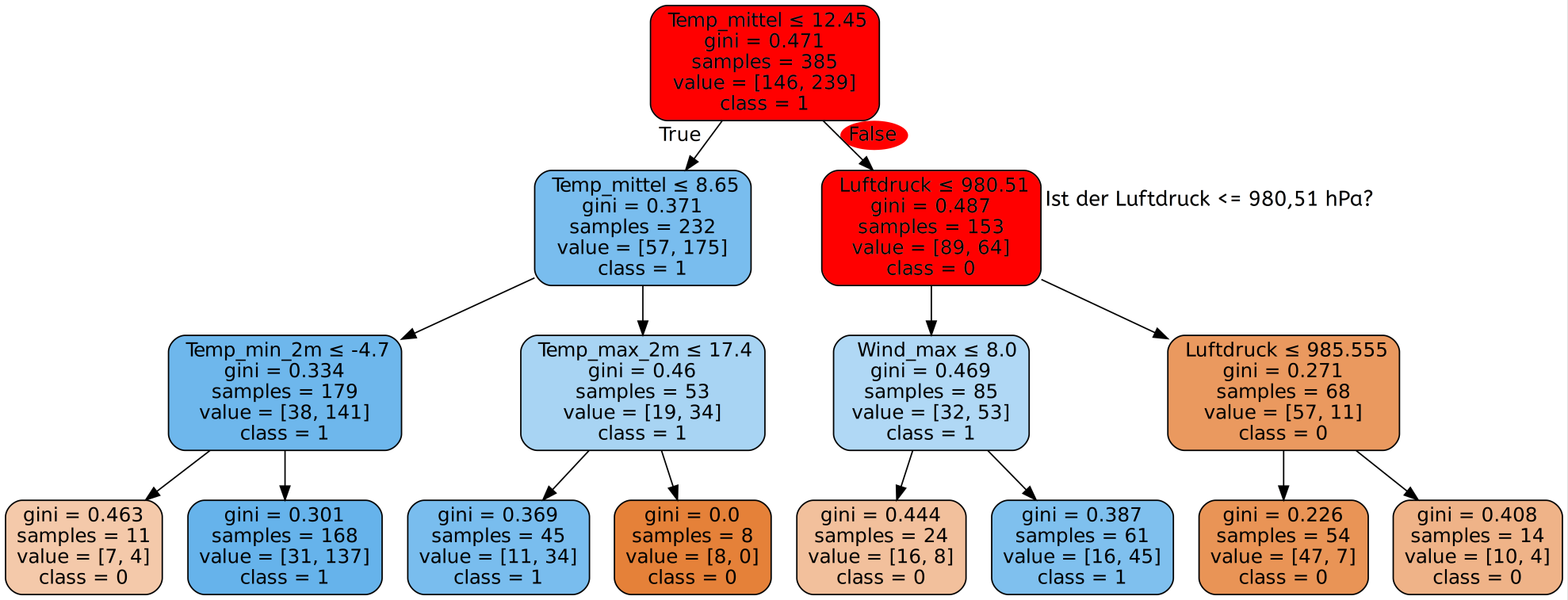
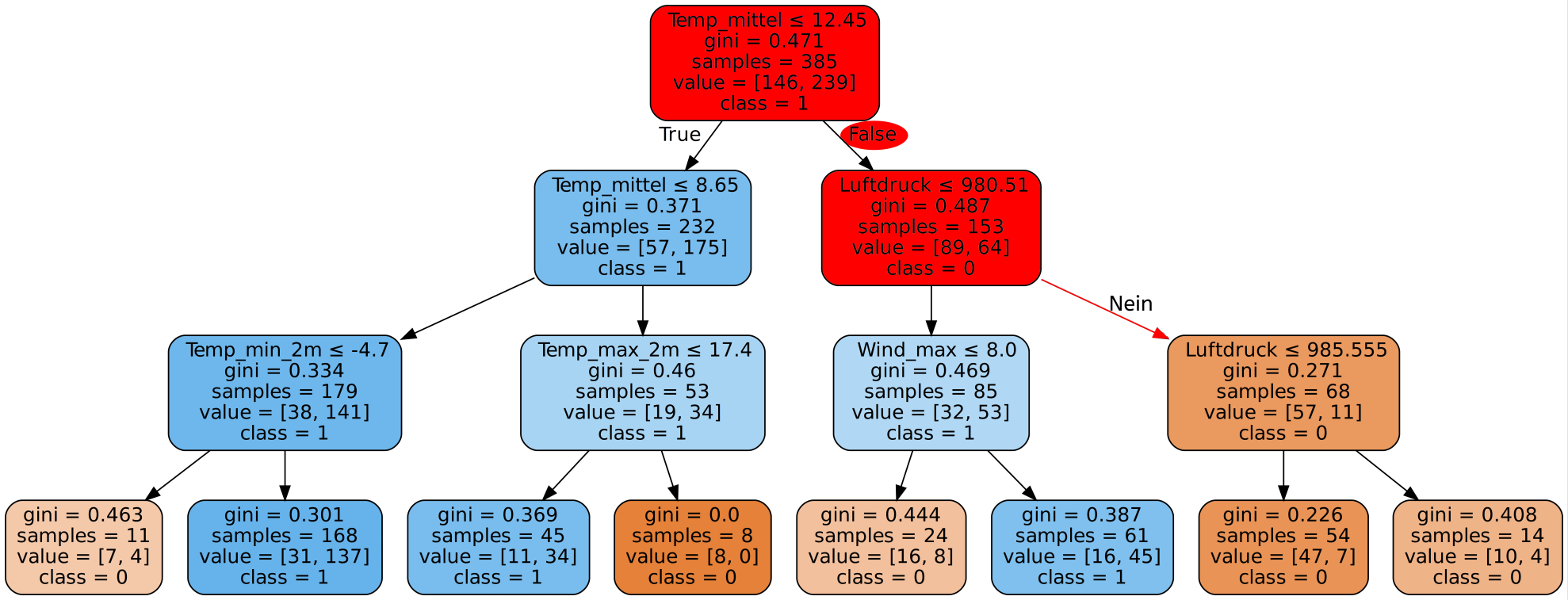
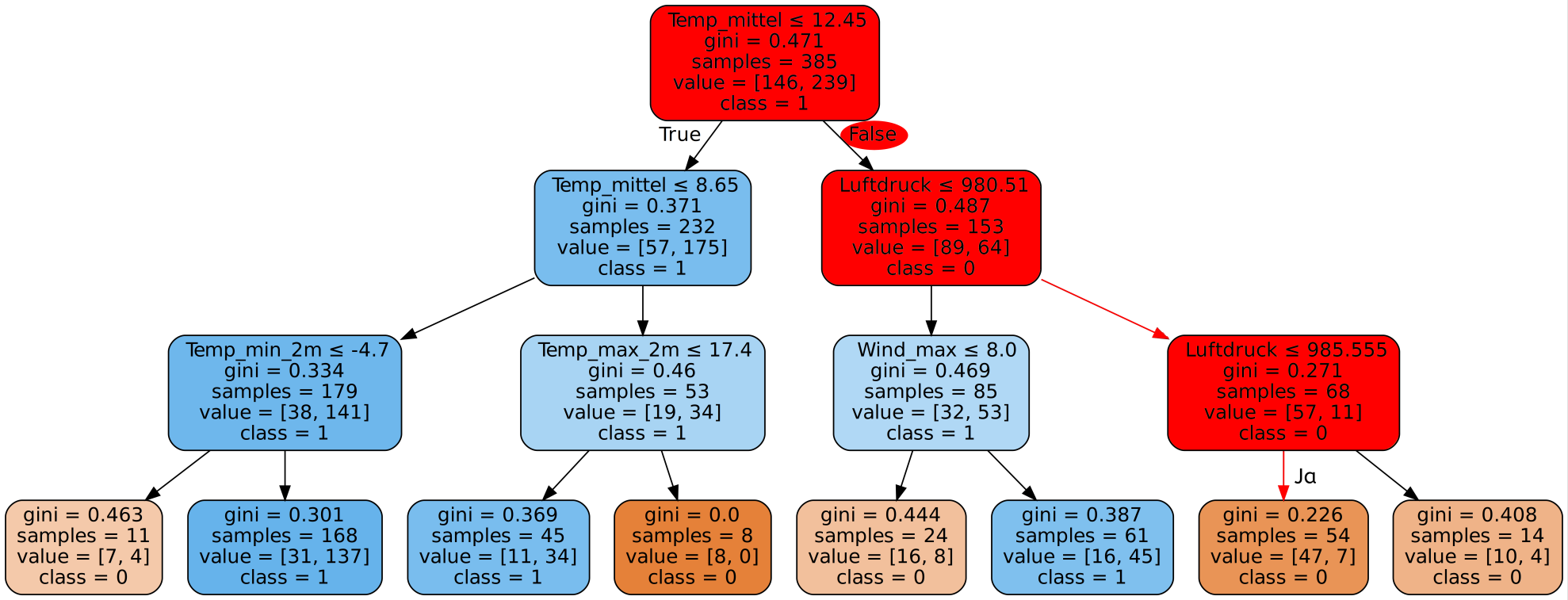
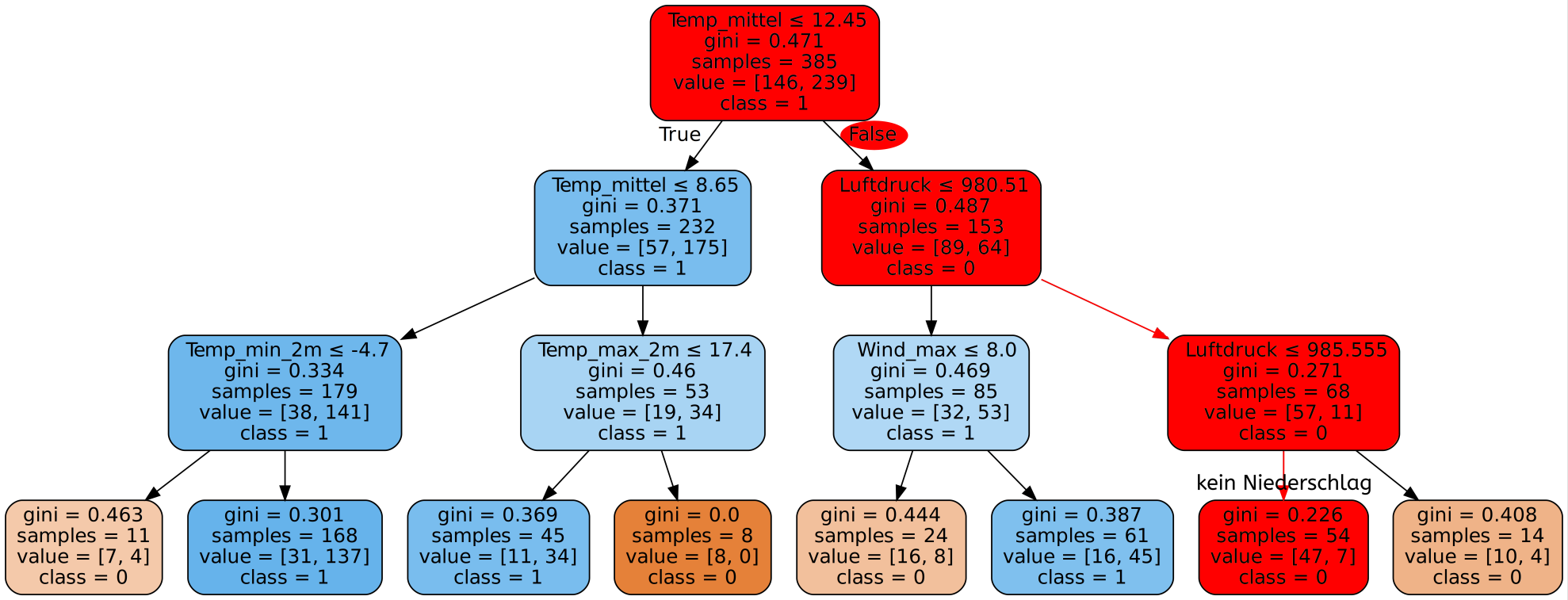
4. min_samples_split
Dieser Parameter ist sehr ähnlich zu min_samples_leaf. Mit min_samples_split wird die minimale Anzahl an Datensätzen festgelegt, die benötigt wird um in einem inneren Knoten einen Split durchzuführen. Auch hier können wir das gleiche Beispiel von oben nehmen. Wenn min_samples_split=30 gilt, so würde der Algorithmus im markierten Knoten keinen Split mehr durchführen, da hier bereits weniger als 30 Datensätze übrig sind. Stattdessen würde der Algorithmus davon ausgehen, dass alle Datensätze in diesem Knoten bereits zu der gleichen Kategorie (Kategorie 1) gehören. Dies entspricht der Vorhersage Niederschlag. An dieser Stelle würde der Baum sich also nicht mehr weiter verzweigen, sondern es würde ein Blatt entstehen mit 26 Datensätzen die alle als Niederschlag klassifiziert wurden.
Nach der Theorie über einige der möglichen Parameter wirst du auf der folgenden Seite die Möglichkeit haben, den Einfluss der Parameter auf die Genauigkeit und die Sensitivität selbst zu beobachten.
Weiter