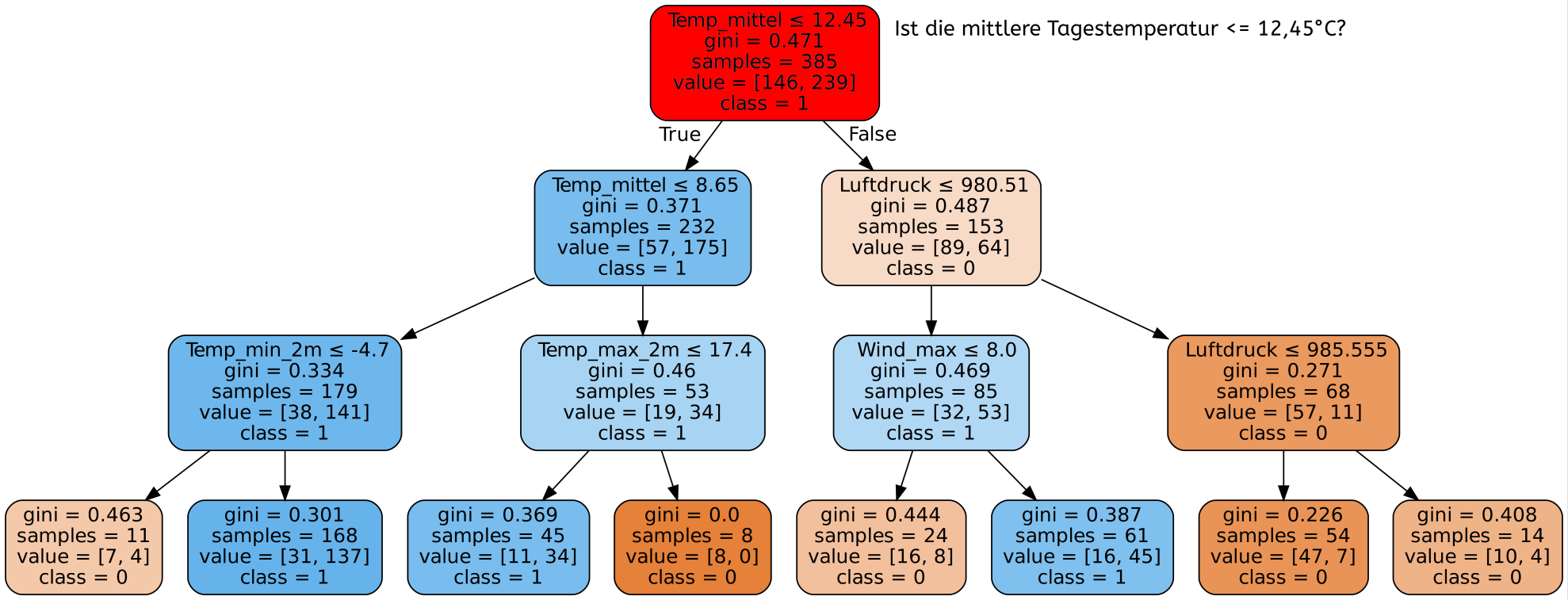
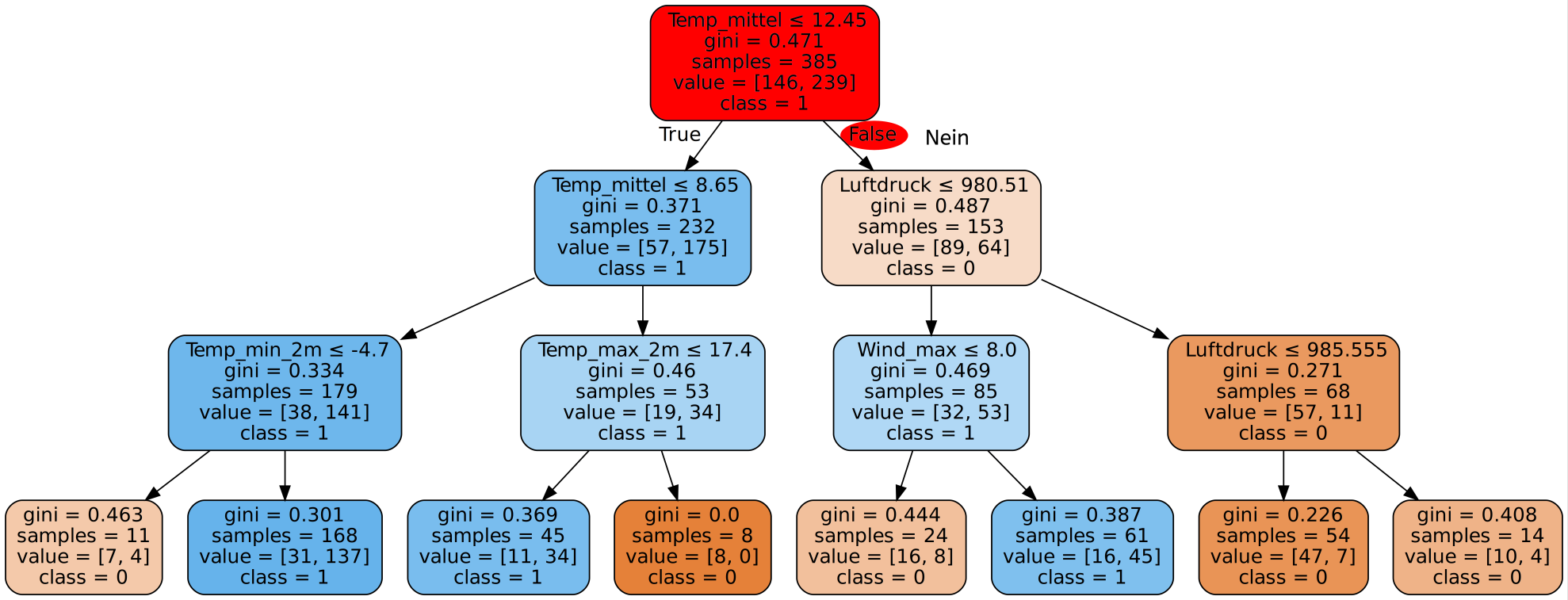
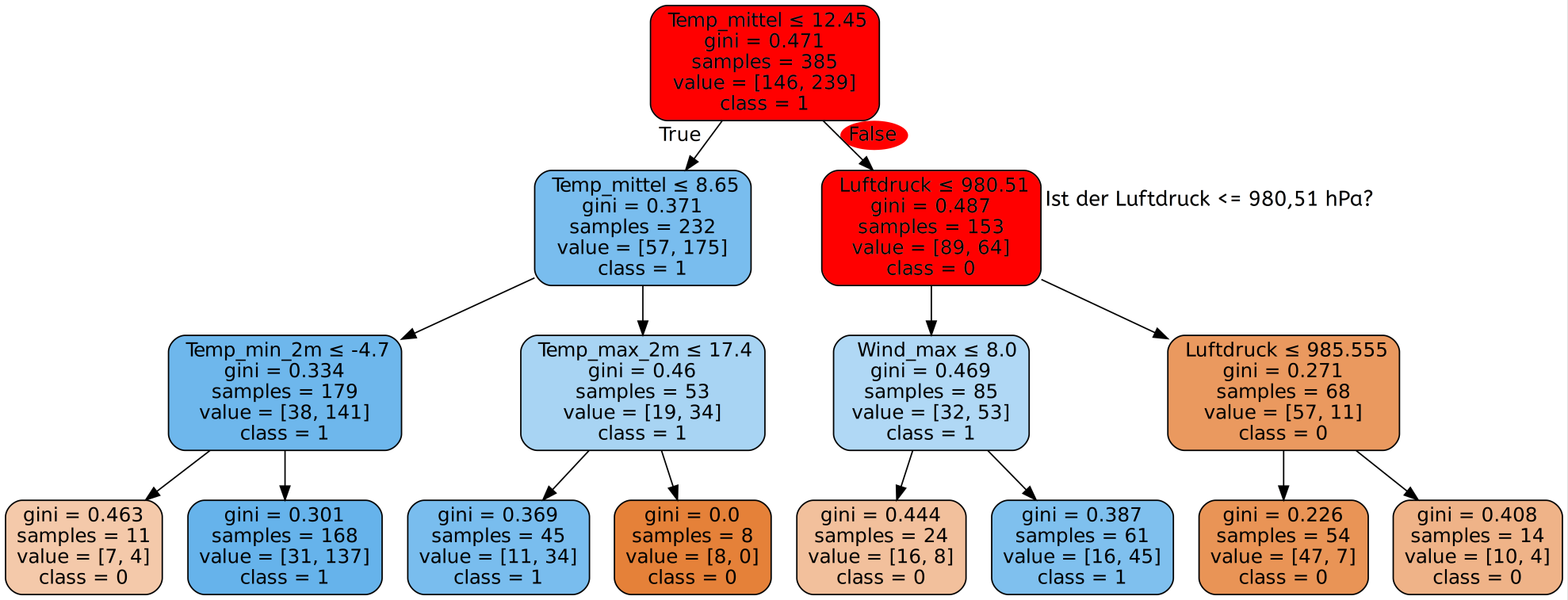
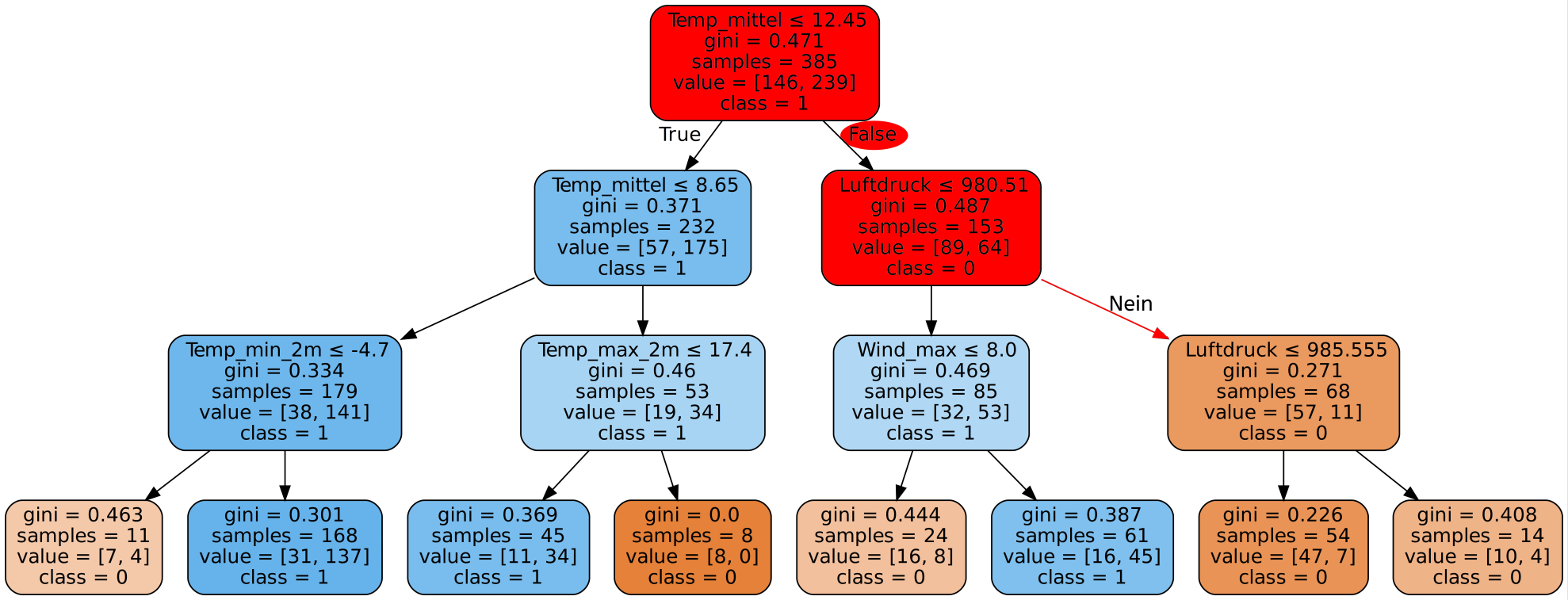
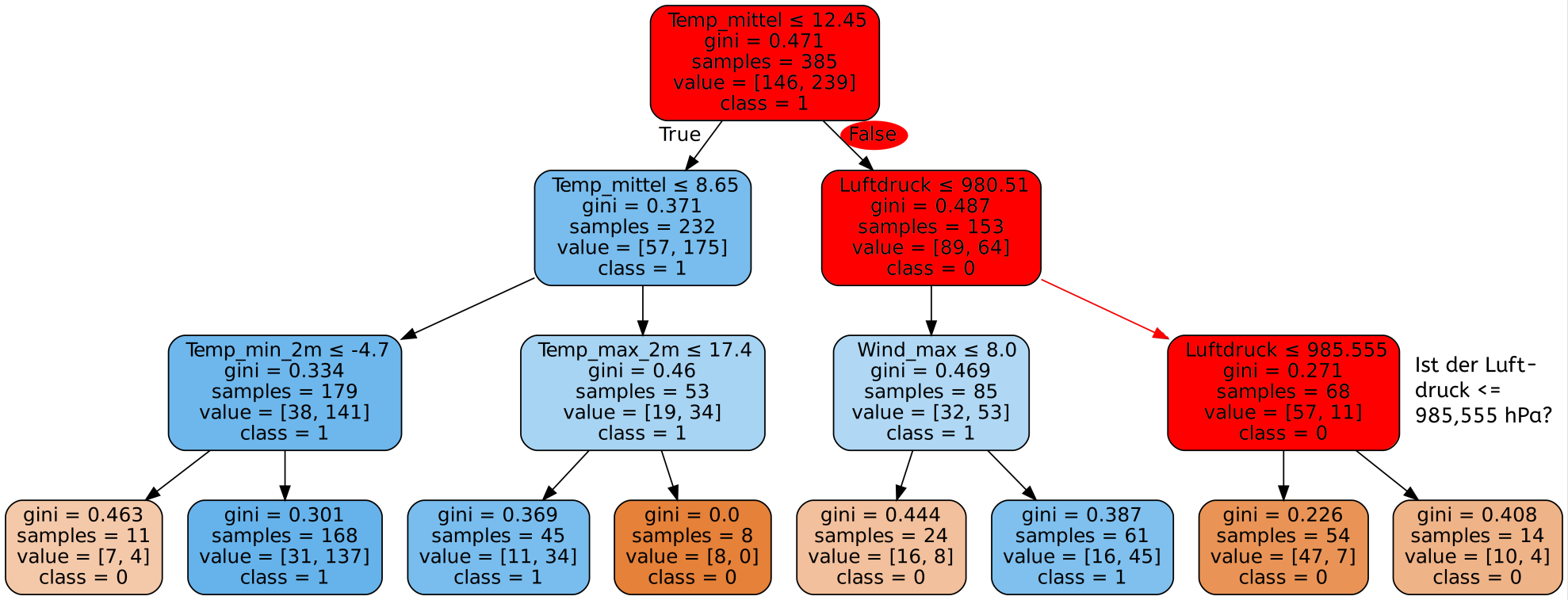
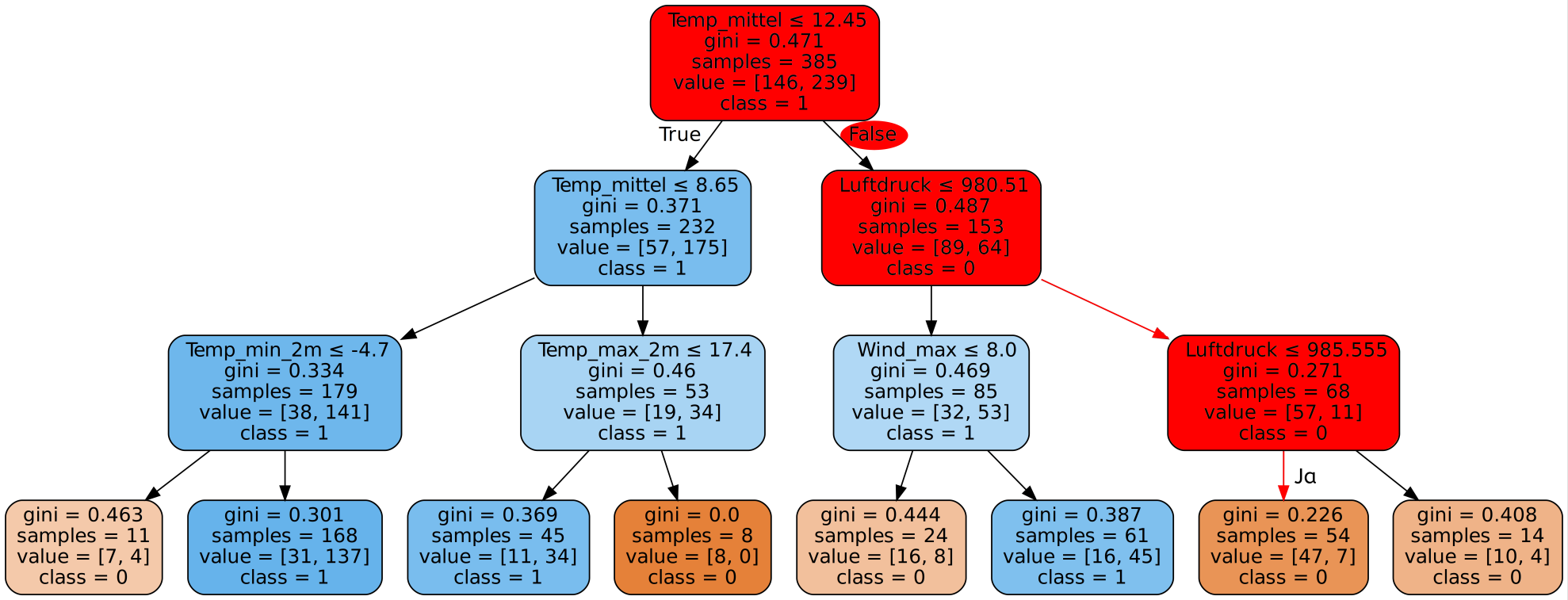
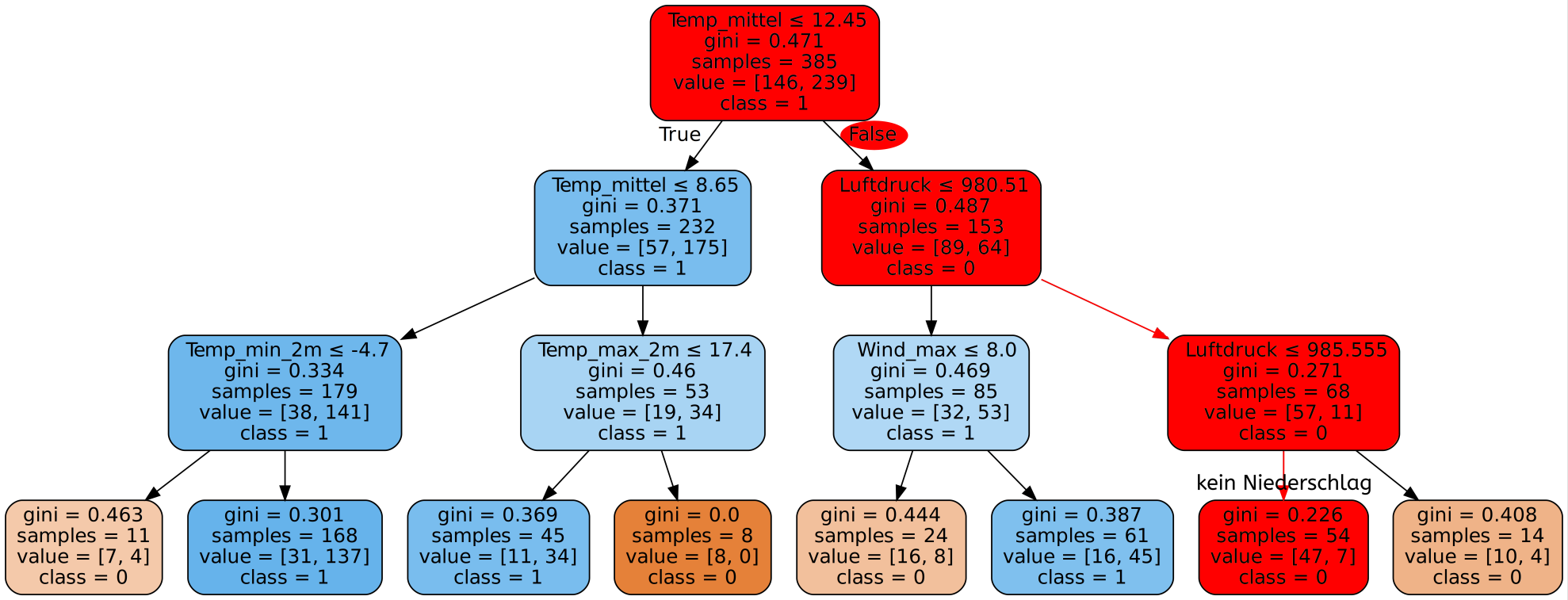
Einführung
Als ein Teilgebiet der Künstlichen Intelligenz beschäftigt sich Maschinelles Lernen, ML, mit dem Erkennen von Mustern in Daten. Dabei sind meist große Datenmengen nötig, um dem Computer zu ermöglichen die zugrundeliegenden Muster und Gesetzmäßigkeiten zu erkennen. Auf der Basis dieser Muster kann der Computer Lösungen entwickeln und im Anschluss Vorhersagen zu den Eigenschaften neuer Daten treffen.
Mittlerweile finden sich immer mehr Programme die Maschinelles Lernen nutzen. Im Alltag bist du sicherlich - vielleicht unbewusst - bereits mit Maschinellem Lernen in Kontakt gekommen und hast davon profitiert.
Beispiele für ML im Alltag sind:
- Spam-Filter in Email-Programmen
- Texterkennung von Handschriften
- Produktempfehlungen beim Online Shopping
- ...
Fallen dir selbst noch weitere ähnliche Beispiele ein?
Verschiedene Arten des Maschinellen Lernens
Beim Maschinellen Lernen werden je nach Anwendungsgebiet eine Vielzahl unterschiedlicher Algorithmen angewandt. Diese sind für das Erkennen der Muster zuständig und lassen sich verschiedenen Kategorien zuordnen. Hauptsächlich unterscheidet man die Kategorien
- überwachtes Lernen
- unüberwachtes Lernen
- bestärkendes Lernen
überwachtes Lernen
Überwachtes Lernen kennzeichnet sich dadurch, dass bei den Daten, auf deren Basis der verwendete Algorithmus die Gesetzmäßigkeiten erkennen und somit lernen soll, das Ergebnis als sogenanntes Label mitgegeben wird.
Beispielsweise werden bei der Bilderkennung von handgeschriebenen Zahlen viele Beispiele der einzelnen Zahlen gesammelt und (oft von Hand) als 1, 2, 3, 4, ... markiert. Diese Bilder und ihre zugehörigen Labels werden dann dem Algorithmus als Trainingsdaten übergeben. Der Algorithmus analysiert den Datensatz und erkennt die Muster und Eigenschaften, die zum Beispiel eine Zahl als 5 klassifizieren. Nach diesem Training ist das Programm dann in der Lage mehr oder weniger gut - je nach Qualität und Menge der Daten, sowie verwendetem Algorithmus - neue und unbekannte Bilder von Zahlen in die Kategorien 1, 2, 3, usw. einzuordnen. Das Programm hat also gelernt welche Eigenschaften das Aussehen einer bestimmten Zahl hat und kann dieses Wissen anwenden.


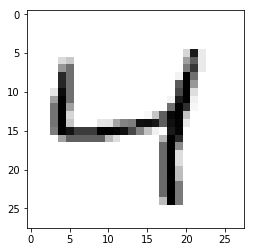
unüberwachtes Lernen
Beim unüberwachten Lernen werden im Gegensatz zum überwachten Lernen dem Computer keine vorgefertigten Beispiele übergeben. Stattdessen erfolgt die Erkennung der Muster und vor allem die Einteilung in verschiedene Kategorien automatisch. Es finden sich in den Trainingsdaten also keine Labels. Ein Beispiel wäre die Einteilung der Kunden eines großen Elektronik-Online-Shops in verschiedene Käufergruppen. Der Algorithmus erkennt ohne Vorgabe die Gemeinsamkeiten und Unterschiede zwischen den einzelnen Kunden und gruppiert diese. So könnte er in unserem Beispiel erkennen, dass 55% der Kunden männlich sind, bevorzugt am Abend einkaufen und sich dabei hauptsächlich für Fernseher und Laptops interessieren, wohingegen 10% der weiblichen Kunden das größte Interesse an Smartphones zeigen. Somit können verschiedene Gruppen gebildet werden, ohne dass durch den Menschen eine Vorgabe gegeben wird. Der Algorithmus hat also selbstständig gelernt ohne Überwachung.
bestärkendes Lernen
Der Name bestärkendes Lernen ergibt sich daraus, dass hier der Algorithmus bestimmte Vorgaben in Form von Belohnungen und Bestrafungen erhält. Der Algorithmus führt selbstständig verschiedene Aktionen auf den gegebenen Daten durch und erhält damit vorher definierte Belohnungen oder - im Falle nicht erwünschter Aktionen - Bestrafungen. Das Ziel ist es, dass der Algorithmus die beste Strategie erlernt, die es ihm ermöglicht eine möglichst hohe Belohnung zu erhalten. Eines der bekanntesten Beispiele für bestärkendes Lernen ist die AlphaGo-KI von Deepmind, die 2016 das äußerst komplexe Strategiespiel Go erlernte, indem sie mehrere Millionen Go-Spiele analysierte und gegen sich selbst spielte um die beste Strategie zu finden. Sie war so erfolgreich, dass sie sogar den amtierenden Weltmeister Lee Sedol schlagen konnte. Diese Art des Maschinellen Lernens kommt dem menschlichen Lernen relativ nahe.
Weiter